Modeling: Ledger Transaction Audit Module
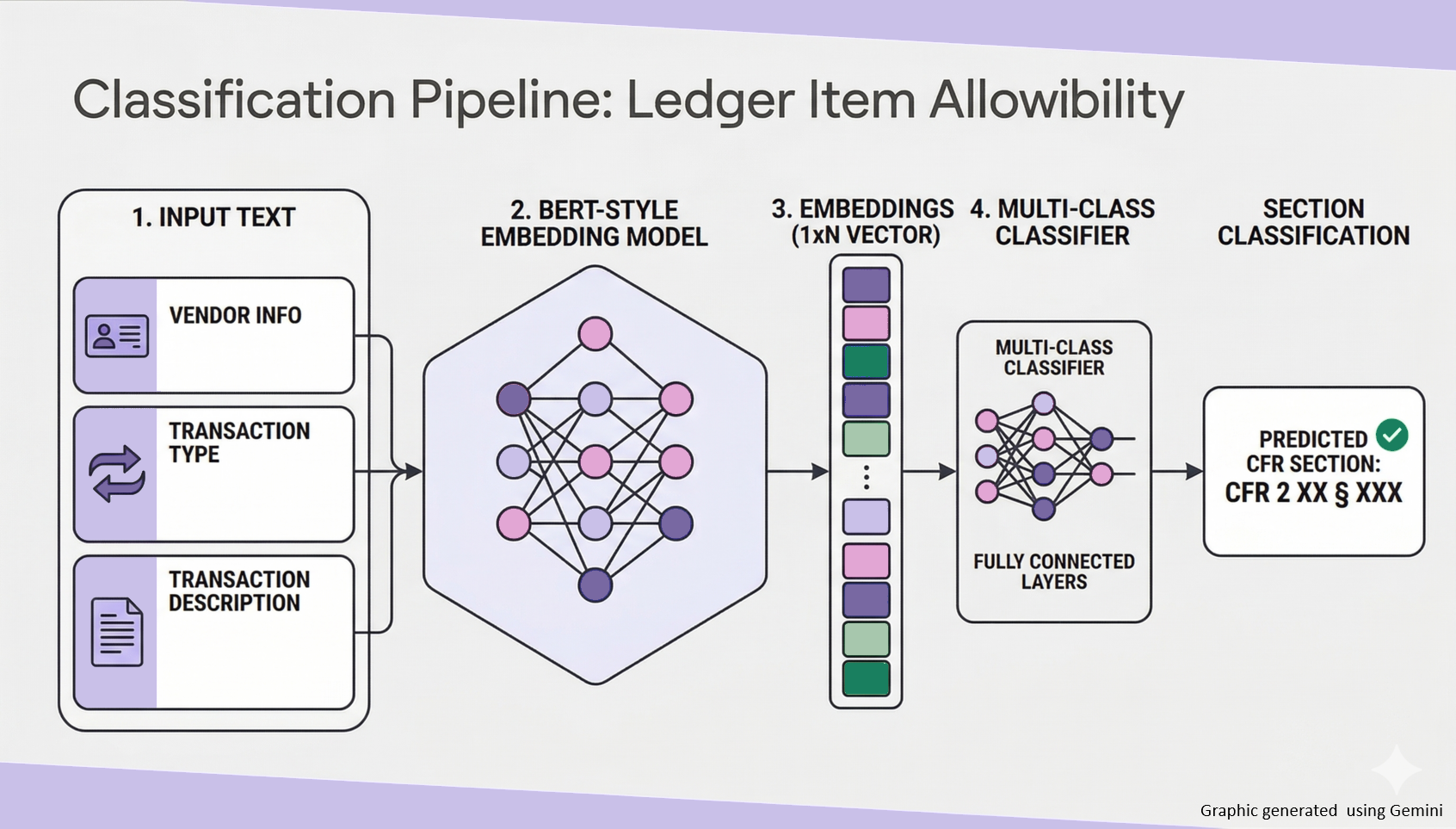
Under the hood, the Ledger Transaction Audit Module is powered by a multiclass classifier based on a BERT-style model. The input consists of the vendor, transaction type, and description from an individual expense. The BERT model encodes this text into embedding feature vectors, and uses a sequence of fully-connected layers to determine the most probable class. This output maps to either “No Violation” or a specific section of the CFR rules that the line item is at risk of violating.
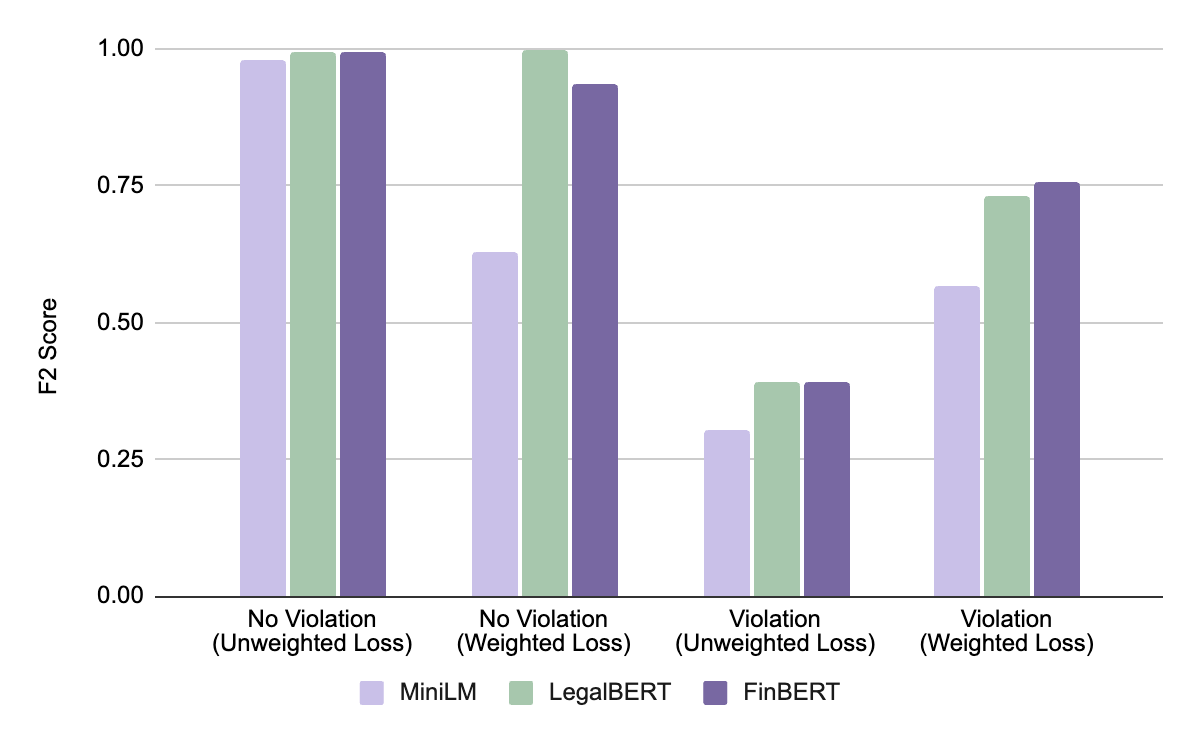
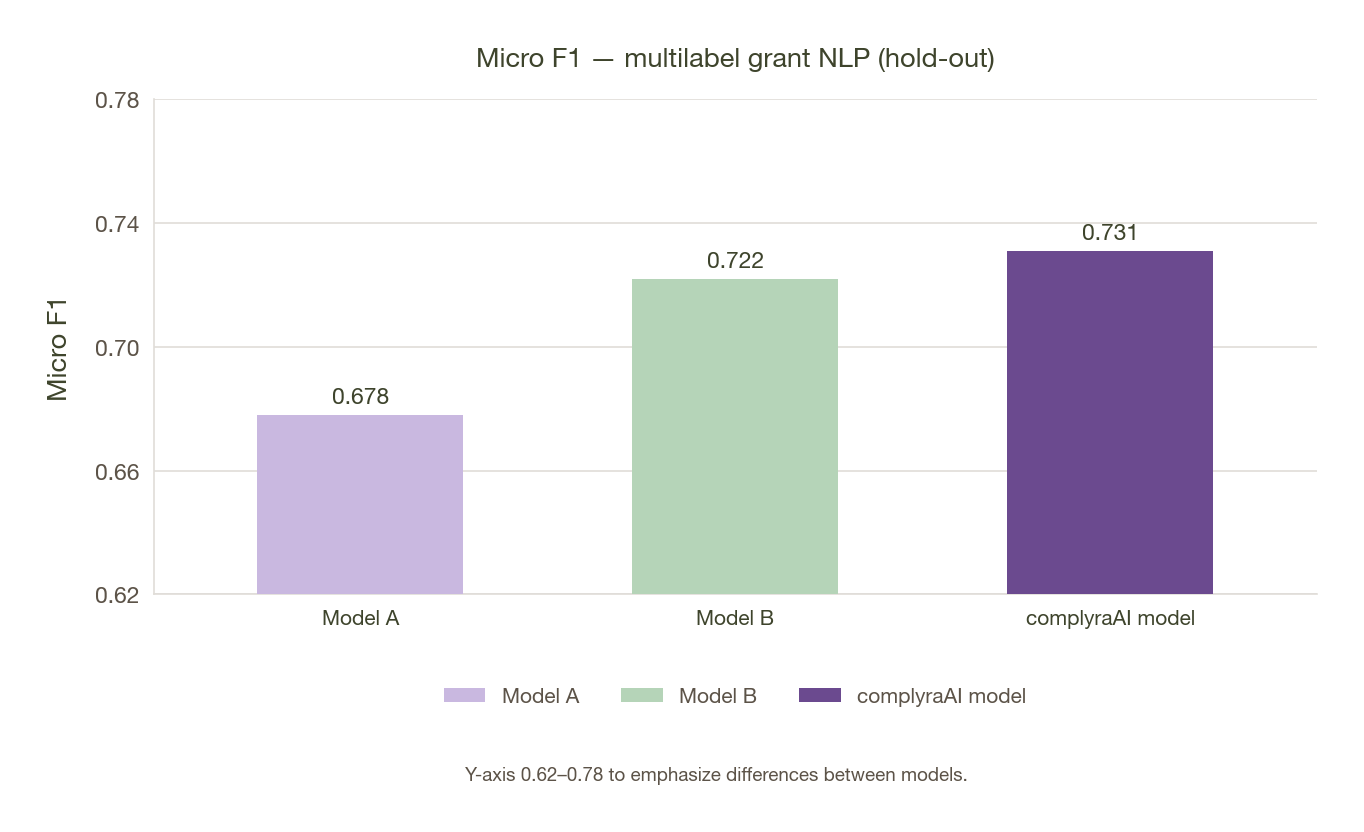
During development, we experimented with three base embedding models. Our baseline, MiniLM, is a task-agnostic sentence encoder. LegalBERT and FinBERT are BERT models that were trained on legal and financial data, respectively. In addition, we experimented with introducing a weighting scheme into the cross-entropy loss function, with weights inversely proportional to class frequency so the model pays more attention to under-represented classes.